
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Stack
- String Method
- Matplotlib
- MySQL
- 파이썬
- python
- 알고리즘 스터디
- 노마드코딩
- Join
- 코딩테스트
- Selenium
- openCV
- programmers
- aws jupyter notebook
- dataframe
- 알고리즘스터디
- 선그래프
- pandas
- 백준
- NumPy
- Algorithm
- 데이터시각화
- 프로그래머스
- 자료구조
- 알고리즘
- type hint
- queue
- 정보처리기사 c언어
- 가상환경
- javascript
Archives
- Today
- Total
조금씩 꾸준히 완성을 향해
[Pandas] 데이터 전처리 / 누락 데이터 처리 (isnull, notnull, dropna, fillna) 본문
Python/Numpy & Pandas
[Pandas] 데이터 전처리 / 누락 데이터 처리 (isnull, notnull, dropna, fillna)
all_sound 2022. 10. 2. 18:10누락데이터 처리
- 데이터의 누락 : 데이터를 입력할 때 빠트리거나 파일 형식을 변환하는 과정에서 데이터가 소실되는 것이 주요 원인
- 일반적으로 유효한 데이터 값이 존재하지 않는 누락 데이터를 NaN(Not a Number)으로 표시
- 머신러닝 모델에 데이터 입력 전 반드시 누락 데이터 제거 혹은 다른 적절한 값으로 대체하는 과정 필요
- 누락 데이터가 많아지면 데이터의 품질이 떨어지고 머신러닝 분석 알고리즘을 왜곡하는 현상 발생
▶ NaN 값 확인
#라이브러리 import
import seaborn as sns
import pandas as pd#titanic 데이터 가져오기
df = sns.load_dataset('titanic')
df.head(5)
#데이터프레임 요약 정보 출력 후 NaN값 개수 확인
df.info()
#deck 열의 NaN값 개수 확인
df.deck.value_counts(dropna=False)
누락 데이터를 찾는 직접적인 방법
- isnull() : 누락데이터면 True반환, 유효한 데이터가 존재하면 False 반환
- notnull() : 유효한 데이터가 존재하면 True 반환, 누락 데이터면 False 반환
#데이터프레임 첫 5행이 누락 데이터인지 여부 확인
df.head().isnull()
df.head().notnull()
▶ 누락 데이터의 개수 확인
- isnull과 notnull을 활용
- isnull은 반환값이 참이면 1, 거짓이면 0으로 판별
- isnull 실행후 sum(axis=0)적용시 참(1)의 합이 구해진다.
#상위 5개 행의 누락 데이터 개수 구하기(isnull)
df.head().isnull().sum(axis=0)
#상위 5개 행의 누락 데이터 개수 구하기(notnull)
df.head().notnull().sum(axis=0)
# for문으로 각 열의 NaN 개수 계산하기 ( isnull.sum()을 사용하지 않는다면 )
missing_df = df.isnull()
for col in missing_df.columns:
missing_count = missing_df[col].value_counts() #각 열의 NaN 개수 파악
try:
print(col, ':', missing_count[True]) #NaN 값이 있으면 개수를 출력
except:
print(col, ':', 0) #NaN 값이 없으면 0개 출력누락 데이터 제거
- 누락 데이터가 들어있는 열 또는 행을 삭제
- 열 삭제 시 분석 대상이 갖는 특성(변수)를 제거
- 행 삭제 시 분석 대상의 관측값(레코드)를 제거
▶ dropna() : 누락데이터 삭제에 사용되는 함수
: thresh, axis, subset, how 등 옵션 사용
- 열삭제
# 누락없는 데이터가 500개 이상인 열만 선택
# deck 열 - 891개 중 688개의 NaN값 -> 203개의 데이터 존재
# dropna() 메소드, thresh옵션 사용
df.dropna(thresh=500, axis=1, inplace=True) # 열 삭제 : axis=1
- 행삭제
# 나이 데이터가 없는 모든 행을 삭제 (891개 중 177개가 NaN)
# dropna 메소드, subset, how, axis 옵션 활용
df_age = df.dropna(subset=['age'], how='any', axis=0)
print(len(df_age)) # 714
| axis = 0 / axis = 1 | 0 : NaN 값이 포함된 행을 drop (default) 1 : NaN 값이 포함된 열을 drop |
| how = 'any' / how ='all' | any : 행 또는 열에 NaN값이 1개만 있어도 drop (default 값입니다.) all : 행 또는 열에 있는 모든 값이 NaN이어야 drop |
| inplace = True / inplace = False | True : 원본 DataFrame 자체에 dropna를 적용 False : 원본 DataFrame는 그대로 두고 dropna를 적용한 새로운 DataFrame을 반환 |
| subset = [ ] | subset을 명시하지 않으면 DataFrame 전체(모든 행 & 모든 열에 대해 dropna를 진행 subset을 명시하면 지정된 적힌 열의 값에 대해서만 dropna를 진행 |
누락 데이터 변경
▶ age열의 NaN 값을 삭제하지 않고 다른 나이 데이터의 평균으로 변경
df.age.head(10)
#age 열의 평균계산 (NaN값 제외, mean 메소드 활용)
age_mean = df.age.mean()
#fillna 메소드 활용해서 NaN값을 평균값으로 변경
df.age.fillna(age_mean, inplace=True)
df.age.head(10)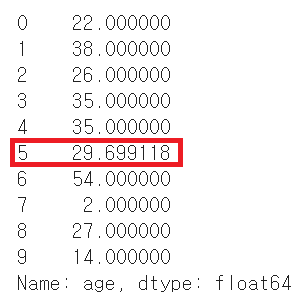
▶ 가장 많이 나온 값으로 NaN값 치환
# embark_town 열의 NaN처리 : 승객들이 가장 많이 승선한 곳의 이름을 찾아 NaN값을 치환
df.loc[825:830, 'embark_town'] # 825~830 열 확인
mos_fruq = df.embark_town.value_counts().idxmax() #idxmax():인덱스 중 가장 많이 나오는 값 찾기
df.embark_town.fillna(mos_fruq, inplace=True) # NaN을 가장 많이 나오는 값으로 변경
df.loc[825:830, 'embark_town'] # 825~830 열 확인
▶ 바로 앞 / 뒤의 값으로 NaN값 치환
#embarked 열의 NaN값을 바로 앞에 있는 828행의 값으로 변경하기
df.loc[829, 'embarked'] # nan# NaN을 바로 앞의 값으로 채움
df.embarked.fillna(method='ffill')[828:831]
# NaN을 바로 뒤의 값으로 채움
df.embarked.fillna(method='bfill')[828:831]
'Python > Numpy & Pandas' 카테고리의 다른 글
| [Pandas] 데이터 전처리 / 데이터 단위 변경, 데이터 타입 변경 (0) | 2022.10.04 |
|---|---|
| [Pandas] 데이터 전처리 / 중복 데이터 확인 및 제거 (duplicated, drop_duplicates) (0) | 2022.10.02 |
| [Pandas] Index 활용 함수(set_idex, reindex, reset_index, sort_index) (0) | 2022.09.29 |
| [Pandas] 행과 열 다루기(삭제, 선택, 추가, 변경) (0) | 2022.09.29 |
| [Pandas] DataFrame 객체 생성과 변경 (0) | 2022.09.25 |
'Python/Numpy & Pandas' Related Articles
more



