
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 선그래프
- 노마드코딩
- 알고리즘
- Join
- 프로그래머스
- dataframe
- 코딩테스트
- python
- MySQL
- 알고리즘 스터디
- type hint
- queue
- aws jupyter notebook
- NumPy
- 자료구조
- programmers
- javascript
- Matplotlib
- 데이터시각화
- 파이썬
- openCV
- Selenium
- 가상환경
- Algorithm
- Stack
- pandas
- 정보처리기사 c언어
- 백준
- 알고리즘스터디
- String Method
- Today
- Total
조금씩 꾸준히 완성을 향해
[논문 리뷰] Federated Learning(연합 학습) /Communication-Efficient Learning of Deep Networks from Decentralized Data 본문
[논문 리뷰] Federated Learning(연합 학습) /Communication-Efficient Learning of Deep Networks from Decentralized Data
all_sound 2023. 7. 6. 19:59
2016년에 Federated Learning(연합 학습) 개념을 가장 처음 소개한 Google의 논문을 리뷰해 보려고 한다.
Communication-Efficient Learning of Deep Networks from Decentralized Data
저자 - H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, Blaise Agüera y Arcas
https://arxiv.org/abs/1602.05629v4
Communication-Efficient Learning of Deep Networks from Decentralized Data
Modern mobile devices have access to a wealth of data suitable for learning models, which in turn can greatly improve the user experience on the device. For example, language models can improve speech recognition and text entry, and image models can automa
arxiv.org
Problem
많은 사람들이 휴대폰, 태블릿 등을 컴퓨팅 디바이스로 사용하고 있다. 이러한 기기에는 강력한 센서(카메라, 마이크, GPS 등)가 탑재돼 있고, 휴대성과 사용성이 높기 때문에 대량의 데이터에 접근이 가능하다.
그러나, 데이터의 민감성 + 거대한 용량 문제들 때문에 중앙 집중식 서버에 데이터를 저장하는데 위험과 책임이 따른다.
Solution
연합학습(Federated Learning)이라는 알고리즘을 통해 이 문제를 해결할 수 있다.
각 클라이언트는 서버에 업로드 되지 않은 로컬 학습 데이터 세트를 가지고 있다. 서버에서 글로벌 모델을 각 클라이언트로 보내면, 클라이언트는 모델에 대한 가중치를 업데이트한 뒤 이를 다시 서버로 전송한다. 서버는 클라이언트들에게 받은 가중치들을 통해 최종적으로 글로벌 모델을 업데이트한다.
이러한 방법을 통해 학습 데이터에 대한 직접 액세스를 하지 않고도 모델 학습을 수행할 수 있다. 따라서 정보 보호 및 보안 위험을 크게 줄일 수 있고, 데이터의 저장 문제도 해결 가능하다.

Federated Optimization(연합 최적화) 주요 특성
- Non-IID : 데이터는 독립항등 분포가 아니다. 특정 사용자의 local dataset을 사용하기 때문에 모집단의 분포를 대표하지 않는다.
- Unbalanced : 사용자마다 디바이스 사용량이 다르므로 local training data가 불균형하게 구성되어 있다.
- Massively distributed : 최적화에 참여하는 클라이언트 수가 방대할 것으로 예상된다. (최대 10의 10승)
- Limited communication : 디바이스와의 커뮤니케이션의 제한적이다. 오프라인 상태, 인터넷 연결 문제 등 다양한 원인이 존재한다.
Algorithm
- Original

전형적인 머신러닝의 학습 방법은 loss function ${f}_i\left(w\right)=l{\left({{x}_i}\ ,{{y}_i}\ ;\ w\right)}$ 을 최소화하는 방향으로 나아간다.
- Fedarated Learning

연합 학습에서는 각각 로컬 클라이언트의 loss가 먼저 구해진다. 그 후, 서버에서 이들을 종합한 loss를 계산하고 이를 최소화하는 방향으로 모델을 업데이트한다.
만약 데이터 분포가 IID라고 가정한다면, ${{{E}_{{P}_k}\left[{F}_k\left(w\right)\right]\ =\ f\left(w\right)}}$ 이 처럼 클라이언트들의 기댓값이 손실 함수와 같아진다.
그런데 본 상황과 같은 Non-IID 상태에서는 클라이언트 당 데이터 분포가 일정하지 않기 때문에 이를 적용할 수 없다. 따라서 위의 식과 같이 서버에서 loss를 구할 때 클라이언트 별로 가중치를 달리 부여하는 형태를 취하는 것이다.
K : 클라이언트들의 개수. (ex. 연합 학습에 참여하는 디바이스의 개수)
$P_k$ : 클라이언트 k의 인덱스들의 집합 (ex. 한 디바이스의 데이터들의 집합)
$N_k$ = ${\left|{P_k}\right|}$ ( $P_k$ 집합의 크기, 즉 $P_k$ 데이터의 개수)
FederatedAveraging Algorithm (연합 평균 알고리즘)
구체적으로 FederatedAveraging 알고리즘을 살펴보자.

C : 각 라운드에서 계산을 수행하는 클라이언트 비율. (C=1 이면 full-batch = non-stochastic, C=0.5 이면 절반의 디바이스만 골라 학습에 참여)
E : 각 라운드에서 각 클라이언트가 로컬 데이터셋에 대해 수행하는 패스 수 (local epoch)
B : 로컬 미니 배치 크기.( B=$\infty $ 이면 full local dataset)
최초로 서버에서 모델의 웨이트 $w_0$를 클라이언트들에게 전송한다. 그리고 업데이트를 진행시킬 클라이언트 데이터를 선별하게 된다. 그 부분이 $Max(C*K, 1)$ 이다. K개의 클라이언트들 중 랜덤으로 C만큼의 비율을 뽑는데, 적어도 하나의 클라이언트는 참여시키게 된다. $S_t$는 선별된 클라이언트들의 집합이다.
그 후 각각의 클라이언트들에서는 병렬적으로 weight update를 진행하게 된다.
클라이언트는 지정된 배치 사이즈, epoch, learning rate를 적용해서 SGD를 수행하여 weight를 업데이트하고, 이 weight들은 다시 서버로 보내지게 된다. 서버에서는 이를 종합해서 최종 weight update를 진행한다.
이 하나의 과정이 여러 round를 걸쳐서 반복된다고 보면 된다.
FederatedSGD
논문에서 FederatedAveraging 말고 FederatedSGD 도 소개가 되는데, 이는 동일한 알고리즘에서 B=$\infty $ 이고 E=1인 케이스를 일컫는다. 즉, 로컬 클라이언트 업데이트 과정에서 full batch로 모든 데이터를 딱 한 번만 업데이트해서 서버로 보낸다는 의미이다.
FedAvg Algorithm의 효율성 검증

MNIST 데이터셋을 사용하여 두 개의 모델을 averging 한 결과를 나타낸 그래프이다. 왼쪽은 초기 weight를 각각 랜덤으로 설정한 케이스인데 averaging 했을 때 loss가 증가하는 것을 볼 수 있다. 반면, 오늘쪽과 같이 동일한 weight에서 출발을 한 경우에는 averaging 했을 때 loss가 최저로 떨어지는 것을 볼 수 있다. 이로써 서버 모델의 동일한 weight를 기반으로 한 연합 평균 알고리즘의 효율성이 입증된다고 볼 수 있다.
실험 결과
본 논문에서는 크게 3가지 데이터를 가지고 수행한 다양한 실험 결과들을 보여준다.
1) MNIST 숫자 인식 Dataset
- 2NN 모델 / CNN 모델 (구체적인 모델 구성은 논문 참조)
- IID / Non-IID 상황 분리 (구체적인 IID / Non-IID 셋팅 방법은 논문 참조)
2) The Complete Works of William Shakespeare Dataset
- 각 연극의 대사가 있는 역할마다 클라이언트 데이터셋 구성 -> 1146개의 클라이언트
- stacked character-level LSTM language model : 각 라인의 문자를 읽은 후 다음 문자를 예측하는 모델 생성
3) Cifar-10 이미지 분류 Dataset
아래 부터는 논문에 수록된 다양한 실험 결과들을 소개한다.

MMIST 데이터 사용. 2NN 모델 97% 정확도, CNN 모델 99% 정확도를 달성한 조건에서의 communication round 측정.
즉, 특정 정확도를 달성하는 데 서버와 클라이언트 간 모델 전송을 얼마나 많이 해야하는지를 나타낸다. 빨간 박스들이 최소 communication 비용을 달성했다고 볼 수 있다.

MMIST 데이터 사용. FedSGD와 FedAVG를 비교해서 학습한 결과를 보여 준다. FedAVG 중에서도 빨간 박스 조건에서 최소 communication 비용을 달성했다.

상위 두 그래프는 MNIST CNN 모델, 하위 두 그래프는 Shakespeare LSTM 모델 사용. Local Batch Size와 Local Epoch의 변화에 따른 정확도 추이를 보여주는 그래프들이다.
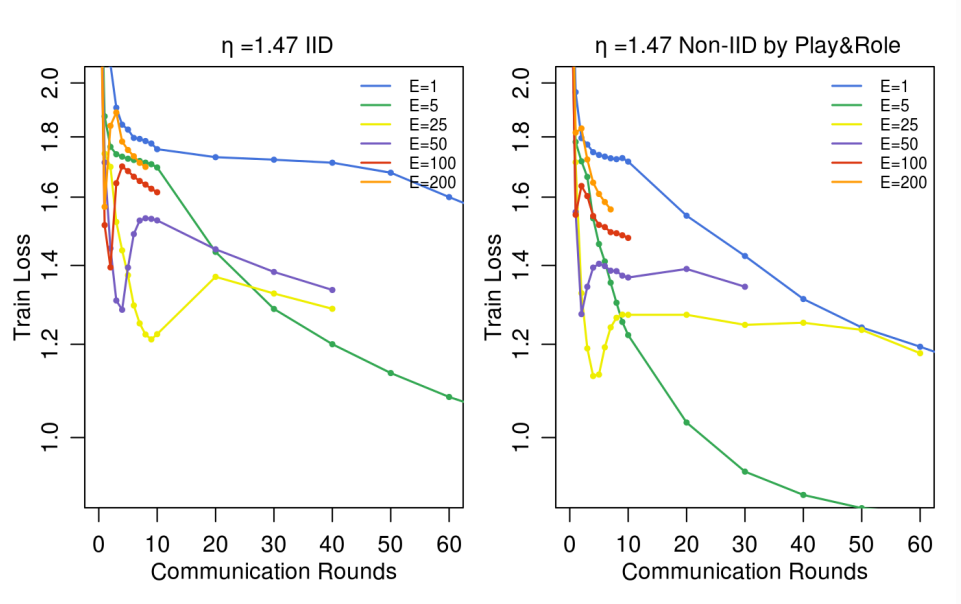
모델을 로컬 epoch 수 별로 학습시켜 성능을 비교한 결과이다. Shakespeare LSTM 모델 사용. B=10, C=0.1로 고정

단일 모델에서 SGD를 한 경우 vs Fedarated Learning을 한 경우, 최대 정확도에 도달하기 위한 round를 비교한 결과이다. 최종적으로 FedAVG의 성능이 가능 높았다고 한다. Cifar 10 데이터 사용. C=1, FedAvg에서는 E=5, B=50 사용

FedSGD, FedAvg 두 알고리즘에 Learning Rate 변화를 적용해 학습한 결과들이다.
그 밖에 부록에 더욱 다양한 실험 결과 그래프와 설명들이 존재하니, 관심 있으신 분들을 가서 참고하시길..!!!
관련 논문을 처음 읽어 보지만 앞으로 연합 학습에 대한 연구가 정말 활발해 질 것 같은 느낌이 든다. 데이터는 정말 방대한데 그걸 종합적으로 모으고 정제하고 저장하고 관리하는 일은 결코 쉬운 게 아니라고 생각한다. 연합 학습을 통해 로컬에서 각각 모델 업데이트를 할 수 있다면 정말 쉽고 빠르게 거대 모델을 생성할 수 있을 것 같다.
그리고 이런 중요한 Task를 이렇게 간단한 알고리즘으로 수행이 가능하다는 사실도 참 놀라웠다. '여러 가중치들을 모아 weighted sum 한다' 라는 것이 핵심 아이디어의 전부라고 해도 과언이 아니다. 이 아이디어를 실제로 구현하고, 수많은 실험을 수행해서 증명해 냈다는 것이 더 대단한 일이긴 하지만.
ChatGPT 같은 거대 모델을 업데이트 할 때도 이 연합 학습을 적용시켜 볼 수 있을 것 같기도 하다. 조만간 디바이스들에도유사한 알고리즘이 적용될 수도 있을 거라 생각한다.
아무튼 재밌고 유익한 논문이었다. 끝!!



