
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 노마드코딩
- queue
- String Method
- programmers
- Algorithm
- 알고리즘
- 데이터시각화
- Matplotlib
- python
- type hint
- Stack
- 자료구조
- 가상환경
- aws jupyter notebook
- 백준
- 알고리즘 스터디
- NumPy
- 파이썬
- pandas
- MySQL
- 코딩테스트
- Join
- openCV
- 프로그래머스
- 선그래프
- 정보처리기사 c언어
- Selenium
- dataframe
- 알고리즘스터디
- javascript
Archives
- Today
- Total
조금씩 꾸준히 완성을 향해
[자료 구조] Array(배열) & List(리스트) 본문
Array (배열) & List (리스트)
데이터를 연속적인 메모리 공간에 저장하고, 저장된 곳의 주소(address, reference)를 통해 매우 빠른 시간에 접근할 수 있는 가장 기본적인 순차적인(sequential) 자료구조
C 언어의 배열
▶ 배열의 저장 및 메모리 할당
int A[4] = {2, 4, 0, 5} // 정수 4개를 저장할 수 있도록 연속적인 메모리 공간 할당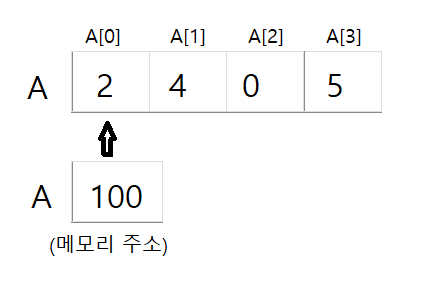
- A[2]의 주소 = A[0]의 시작 주소 + 2 * 4 bytes (index=2, sizeof(int)=4) //108번째
- 배열의 시작 주소, 저장된 값의 종류(바이트 개수), 몇 번째에 저장되어 있는지를 나타내는 인덱스(index) 세 가지 정보만으로 값이 저장된 곳의 주소를 계산할 수 있다 => 메모리 주소가 주어지면 단위 시간에 값을 읽거나 저장할 수 있음
▶ 읽기와 쓰기 연산: O(1) 시간
- 읽기 예: print(A[2]) # A[2]의 값을 읽는 연산
- 쓰기 예: A[2] = 8 # A[2]의 메모리에 값 8을 저장하는 연산
- 읽기 쓰기 예 : A[2] = A[2] + 1 #A[2]의 값을 읽어 +1을 한 후 A[2]의 메모리 값에 저장하는 연산
Python의 List
▶배열의 저장 및 메모리 할당
A = [2, 4, 0, 5]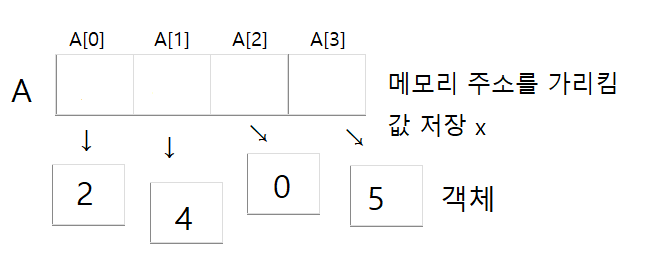
▶ 값 재할당 ex) A[2] = A[2] + 1

- C 언어 배열의 셀에는 실제 값(데이터)이 저장된 형식이지만, Python 리트스의 셀에는 데이터가 아닌 데이터가 저장된 곳의 주소(address 또는 reference)가 저장된다.
- 항상 객체의 주소만 저장하기 때문에, 리스트의 셀의 크기를 메모리의 주소를 표현할 수 있는 (4 바이트 또는) 8 바이트로 고정하면 된다. 모든 셀의 크기가 같기 때문에 index에 의해 O(1) 시간 접근이 가능
▶ Python list 의 다양한 함수
| A.append(value) | 맨 오른쪽 (뒤)에 새로운 값 value를 삽입 | |
| pop | A.pop() | 맨 오른쪽 값을 지움 |
| A.pop(i) | A[i] 값을 지운 후 리턴 (i번째 오른쪽 값들은 왼쪽으로 한 칸씩 당겨져, cell의 수가 하나 감소) | |
| A.insert(i, value) | A[i]에 value 할당 (A[i], A[i+1], ...값들은 오른쪽으로 한 칸씩 이동해 A[i]를 비운 후, value 값 저장) | |
| A.remove(value) | value를 찾아 제거 (value 오른쪽의 값들은 왼쪽으로 한 칸씩 이동해 빈 공간을 메꿈) | |
| A.index(value): | value 값이 처음으로 등장하는 index 리턴 | |
| A.count(value) | value 값이 몇 번 등장하는지 횟수를 세어 리턴 | |
| A[i:j] | A[i], ..., A[j-1] 까지 잘라낸 새로운 리스트 생성하여 리턴 (slicing) | |
| value in A | A에 value가 있으면 True, 없으면 False 리턴 | |
C의 배열 vs Python의 List
▶ 연산
- C의 배열은 읽기/쓰기 연산만 제공하는 제한된 자료구조이지만, Python list는 다양한 연산들을 제공해 편의성이 높음
▶ 메모리의 할당
- Dynamic array! Python의 리스트는 동적 배열이다!
=> C 언어의 배열과 달리 용량을 자동조절 - C의 배열에서 값을 추가하려면 에러 -> 메모리를 할당하는 함수를 사용해 새로운 배열에 옮겨가야 함
- Python List는 필요에 따라 크기(셀의 개수)가 자동으로 증가, 감소
▶ Python List의 메모리 할당 예시
import sys
a = []
# 빈 리스트도 56 바이트 무조건 할당
print(sys.getsizeof(a)) # 56
a.append("hello")
# append 연산 후 88 바이트로 재 할당
print(sys.getsizeof(a)) # 88
b = 1
# 정수 변수 : 4바이트가 아닌 28 바이트 할당
print(sys.getsizeof(b)) # 28- append 또는 insert 연산을 위한 공간(메모리)이 부족하면 더 큰 메모리를 할당받아 새로운 리스트를 만들고 이전 리스트의 값은 모두 이동한다.
- 반대로 pop 연산을 하면서 실제 저장된 값의 개수가 리스트 크기에 비해 충분히 작다면 더 작은 크기의 리스트를 만들고 모두 이동한다.
- 동적 배열인 list를 위해선 python 내부적으로 현재 list의 크기(capacity)와 list에 저장된 실제 값의 개수(n)를 알고 있어야 한다.
- 추가 작업을 위한 메모리가 필요하므로 빈 리스트는 0바이트보다 클 수 밖에 없다 (초기값 예: capacity = 1, n = 0)
Python List 함수들의 수행시간
| 연산 | 평균 | 최악의 경우 |
| Copy | O(n) | O(n) |
| Append[1] | O(1) | O(1) |
| Pop last | O(1) | O(1) |
| Pop intermediate[2] | O(n) | O(n) |
| Insert | O(n) | O(n) |
| Get Item | O(1) | O(1) |
| Set Item | O(1) | O(1) |
| Delete Item | O(n) | O(n) |
| Iteration | O(n) | O(n) |
| Get Slice | O(k) | O(k) |
| Del Slice | O(n) | O(n) |
| Set Slice | O(k+n) | O(k+n) |
| Extend[1] | O(k) | O(k) |
| Sort | O(n log n) | O(n log n) |
| Multiply | O(nk) | O(nk) |
| x in s | O(n) | |
| min(s), max(s) | O(n) | |
| Get Length | O(1) | O(1) |
'DataStructure & Algorithm > 이론 정리' 카테고리의 다른 글
| 그리디 알고리즘(탐욕법) / Greedy Algorithm (0) | 2022.10.10 |
|---|---|
| Python 알고리즘의 성능 평가 (1) | 2022.10.10 |
| [자료 구조] Queue (0) | 2022.10.03 |
| [자료 구조] Stack (0) | 2022.10.02 |
| 알고리즘의 시간복잡도(Time Complexity) / Big-O 표기법 (0) | 2022.09.26 |
'DataStructure & Algorithm/이론 정리' Related Articles
more



