
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 알고리즘스터디
- 노마드코딩
- 정보처리기사 c언어
- programmers
- NumPy
- Selenium
- Matplotlib
- 데이터시각화
- String Method
- 자료구조
- Stack
- 파이썬
- MySQL
- 프로그래머스
- python
- dataframe
- 선그래프
- 코딩테스트
- aws jupyter notebook
- type hint
- Algorithm
- pandas
- 백준
- queue
- 가상환경
- 알고리즘
- Join
- openCV
- javascript
- 알고리즘 스터디
Archives
- Today
- Total
조금씩 꾸준히 완성을 향해
[Pandas] 데이터프레임 연결 (concat, merge, join) 본문
데이터 프레임 연결
- 데이터프레임의 구성 형태와 속성이 같다면 행/열 중 어느 한 방향으로 이어붙여서 데이터의 일관성 유지
- 데이터프레임의 형태를 유지하면서 이어 붙이는 개념
concat
▶ DataFrame
#데이터 확인
df1
df2
# 데이터 프레임 행방향 연결
pd.concat([df1, df2], axis=0, ignore_index=False)
#ignore_index=False 가 default (인덱스를 적용시켜 결합)
pd.concat([df1, df2], axis=0, ignore_index=True)
#ignore_index=True : 인덱스를 무시하고 결합(axis = 0 => 열 인덱스는 적용, 행 인덱스는 적용 안함)
# 데이터 프레임 열방향 연결
pd.concat([df1, df2], axis=1)
#inner join : 교집합 결합
pd.concat([df1, df2], axis=1, join='inner')
pd.concat([df1, df2], axis=1, join='inner', ignore_index=True)
#ignore_index=True : 인덱스를 무시하고 결합(axis = 1 => 행 인덱스는 적용, 열 인덱스는 적용 안함)
▶ Series
# 시리즈 확인
sr1
sr2
sr3
# 데이터프레임 + 시리즈
pd.concat([df1, sr1], axis=1)
pd.concat([df2, sr2], axis=1)
# 시리즈 + 시리즈
pd.concat([sr1, sr3], axis=1) #시리즈와 시리즈를 열방향으로 연결 => 데이터프레임
pd.concat([sr1, sr3], axis=0) #시리즈와 시리즈를 행방향으로 연결 => 시리즈
merge
- concat()은 데이터프레임을 이어 붙이듯 연결
- merge()함수는 SQL 의 join 명령과 비슷한 방식
- 어떤 기준에 의해 두 데이터프레임을 병합하는 개념
- 기준이 되는 열이나 인덱스를 키(key)라고 하고, 키가 양쪽 데이터프레임에 모두 존재해야 함
# 데이터프레임 확인
df1.head(3)
df2.head(3)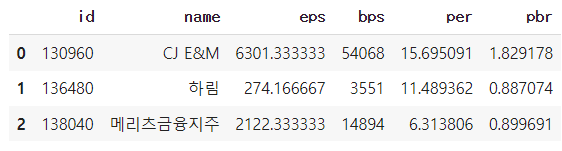
# df1과 df2를 병합(교집합)
pd.merge(df1, df2) # defalut: inner join(교집합), on='id'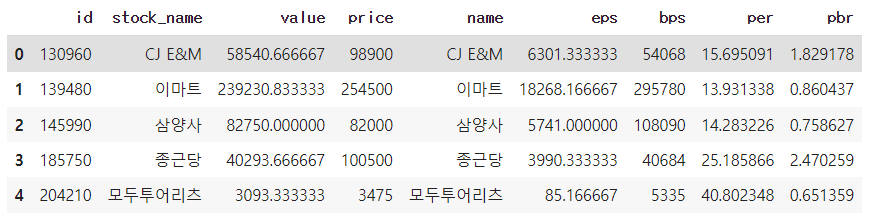
# df1과 df2를 'id'열을 기준으로 병합(합집합)
pd.merge(df1, df2, how='outer', on='id') #합집합

# df1을 기준으로 df1의 'stock_name'열과 df2의 'name'열을 병합
pd.merge(df1, df2, how='left', left_on = 'stock_name', right_on = 'name')
# df2을 기준으로 df1의 'stock_name'열과 df2의 'name'열을 병합
pd.merge(df1, df2, how='right', left_on = 'stock_name', right_on = 'name')
#df1에서 5000원 미만인 항목과 df2 병합
pd.merge(df1[df1.price < 5000], df2)
join
- df1.join(df2, how='')
- merge를 기반으로 작동방식이 유사
- 다만 join은 행 인덱스 기준 결합
# 공통 index를 사전에 설정해야함
df1.set_index('id', inplace=True)
df2.set_index('id', inplace=True)df1.join(df2, how='inner')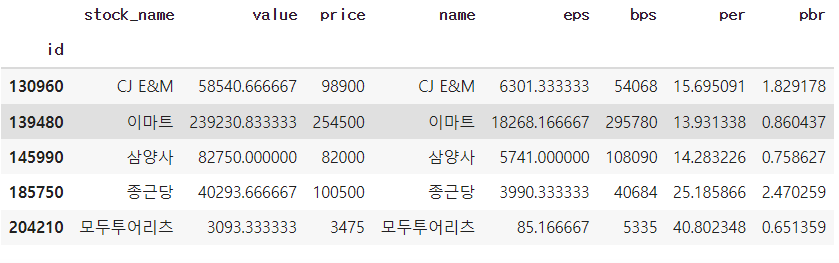
'Python > Numpy & Pandas' 카테고리의 다른 글
| [Pandas] 피벗 테이블(Pivot Table) & 멀티 인덱스(MultiIndex) (0) | 2022.10.10 |
|---|---|
| [Pandas] 그룹객체 생성과 그룹연산 (Groupby, agg, transform, filter, apply) (0) | 2022.10.10 |
| [Pandas] 함수 매핑(mapping) / apply, applymap, pipe (0) | 2022.10.06 |
| [Pandas] 시계열 데이터 생성, 변환, 분리, 인덱싱(to_datetime, to_period, date_range, period_range 등) (0) | 2022.10.05 |
| [Pandas] 범주형(category) 데이터처리 / 구간분할(pd.cut, np.histogram) (0) | 2022.10.04 |
'Python/Numpy & Pandas' Related Articles
more



