
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Selenium
- 데이터시각화
- 가상환경
- 코딩테스트
- 백준
- dataframe
- openCV
- 알고리즘 스터디
- Stack
- Algorithm
- 정보처리기사 c언어
- 선그래프
- python
- MySQL
- Join
- 알고리즘
- 프로그래머스
- pandas
- programmers
- aws jupyter notebook
- queue
- type hint
- 파이썬
- Matplotlib
- NumPy
- 노마드코딩
- 알고리즘스터디
- String Method
- 자료구조
- javascript
Archives
- Today
- Total
조금씩 꾸준히 완성을 향해
[Pandas] 그룹객체 생성과 그룹연산 (Groupby, agg, transform, filter, apply) 본문
Python/Numpy & Pandas
[Pandas] 그룹객체 생성과 그룹연산 (Groupby, agg, transform, filter, apply)
all_sound 2022. 10. 10. 22:26그룹 연산
특정 기준을 적용하여 데이터를 몇 개의 그룹으로 분할하여 처리하는 것
- 복잡한 데이터를 어떤 기준에 따라 여러 그룹으로 나눠서 분석
- 데이터를 집계, 변환, 필터링에 효과적
- 총 3단계
- 분할 (split): 데이터를특정 조건에 의해 분할
- 적용 (apply): 데이터를 집계, 변환, 필터링하는데 필요한 메소드 적용
- 결합 (combine) :처리 결과를 하나로 결합
Groupby
▶ 하나의 열 기준으로 그룹화
# 데이터 확인
df.head()
# groupby로 class 열을 기준으로 분할하여 grouped 변수에 저장
grouped = df.groupby('class')
grouped
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x7effc0730e50># calss의 unique 값 확인
df['class'].unique()
# ['Third', 'First', 'Second']
# Categories (3, object): ['First', 'Second', 'Third']# 그룹객체 출력
for key, group in grouped:
print(key)
print(group.head(2))
# 그룹객체의 평균 확인
grouped.mean()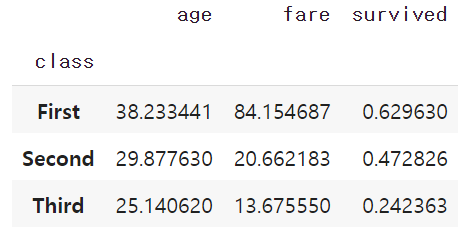
# groupby로 class 열을 기준으로 분할 후, 'Third' 그룹만 출력
df.groupby('class').get_group('Third')
▶ 여러 열을 기준으로 그룹화
#'class'와 'sex'열을 기준으로 그룹화 후 변수에 저장
grouped_two = df.groupby(['class', 'sex'])
# 그룹객체 출력
for key, group in grouped_two:
print(key)
print(group.head(2))
# 그룹객체의 평균 확인
grouped_two.mean()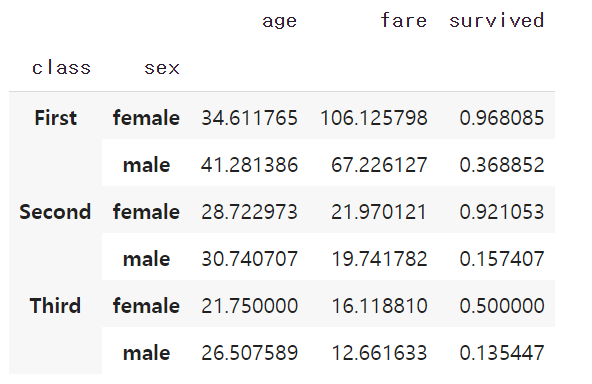
# 'Third'그룹 이면서 'female'그룹인 데이터 확인
grouped_two.get_group(('Third', 'female'))
집계 함수
▶ 데이터 집계 (aggreagation)
- mean, max, min, sum, count, size, var, std, describe, first, last 등의 집계 함수
# 그룹 객체의 표준편차 구하기
grouped.std()
# 그룹 객체의 데이터의 개수
grouped.size() # = value_counts()
# 그룹객체의 통계정보 확인
grouped.describe()
# 그룹객체의 fare열의 표준편차
grouped.fare.std()
agg
▶ group객체.agg(매핑함수)
- 집계 연산을 처리하는 사용자 정의 함수를 그룹 객체에 적용시 agg 메소드 사용
# 사용자 함수 정의
def min_max(x):
return max(x) - min(x)
# 그룹객체에 적용
grouped.agg(min_max)
▶ 여러 열, 여러 함수 적용
- group객체.agg([함수1, 함수2, 함수3,...])
- group객체.agg({'열1': 함수1, '열2' : 함수2,....}]
# 그룹객체에 여러 함수 적용
grouped.agg([min, max])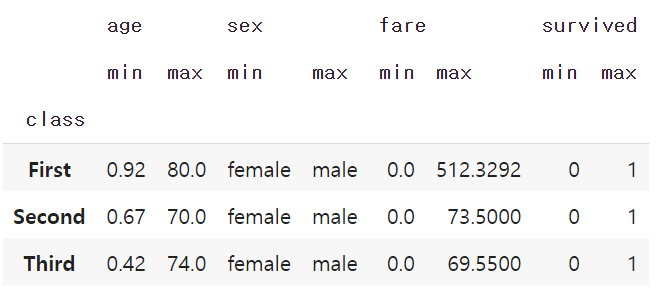
# 열마다 다른 함수 적용
grouped.agg({'fare': ['min', 'max'], 'age': 'mean'})
transform
▶ group객체.transform(매핑함수)
- agg는 각 그룹별 데이터에 함수를 구분 적용하고 그룹별로 결과를 집계
- transform은 그륩별 각 원소에 함수를 적용하지만 그룹별 집계 대신 각 원소의 본래 행 인덱스와 열 이름을 기준으로 연산 결과 반환
# z-score를 계산하는 사용자 함수 정의
def zscore(x):
return ((x - x.mean()) / x.std())# 전체 데이터에 함수 적용
grouped.age.transform(zscore)
#그룹별로 적용되는 게 아니라 전체 데이터에 적용 =>데이터 하나하나에 적용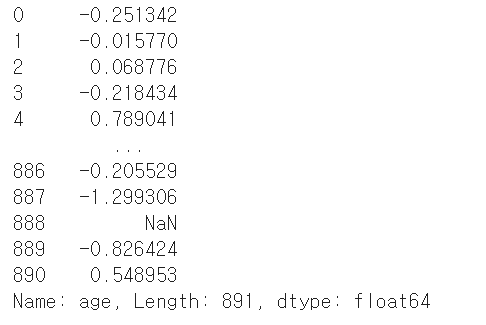
grouped.agg([min, max]) # 그룹의 값을 가지고 계산하는 함수
filter
▶ group객체.filter(조건식 함수)
- 그룹 객체에 filter를 적용할 때 조건식을 가진 함수를 전달하면 조건의 참인 그룹만을 남긴다.
# 그룹객체에서 데이터 개수가 200개 이상인 그룹만 반환
grouped.filter(lambda x : len(x) >= 200) # 'First', 'Third' 그룹만 반환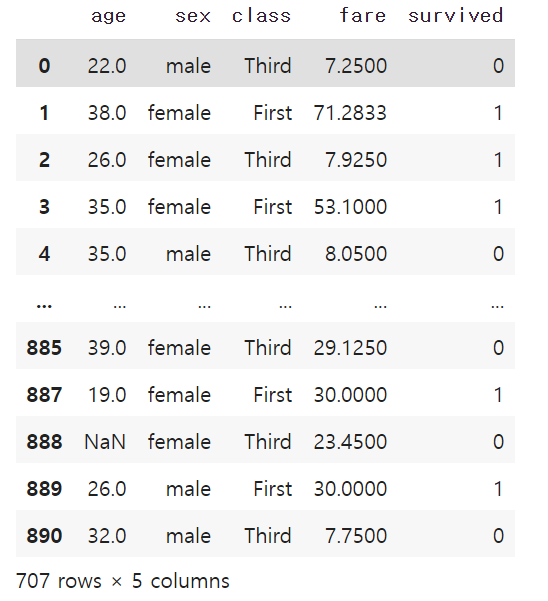
# 그룹객체에서 age열의 데이터 평균이 30보다 작은 그룹만 추출하여 데이터프레임으로 반환
grouped.filter(lambda x: x.age.mean() < 30)
apply
▶ 그룹객체.apply(매핑함수)
- apply 는 개별 원소를 특정 함수에 일대일 매칭. 그룹 객체에도 적용 가능
# 그룹객체의 그룹별 요약 통계정보 집계
grouped.apply(lambda x: x.describe()).head(10)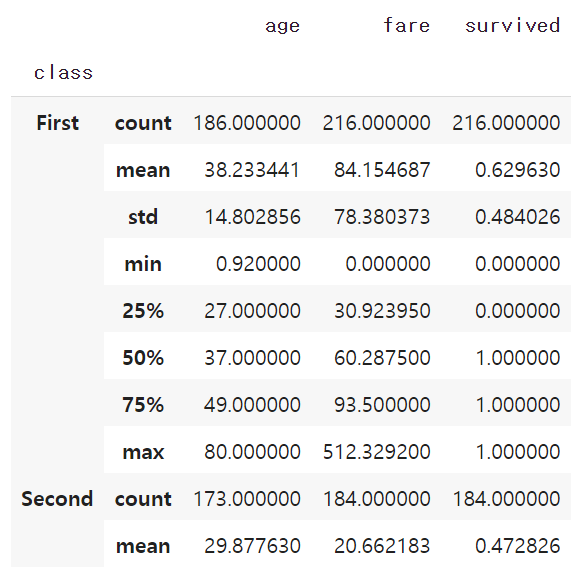
# 필터링 : age열의 데이터 평균이 30보다 작은 그룹만 필터링하여 출력
grouped.apply(lambda x: x.age.mean() < 30)
# 주의!! bool 값만 출력 => 정보만 확인 가능
# apply로 필터링한 데이터 출력 과정
# 필터링한 그룹객체 변수로 저장
age_ft = grouped.apply(lambda x: x.age.mean() < 30)
age_ft.index
#CategoricalIndex(['First', 'Second', 'Third'], categories=['First', 'Second', 'Third'], ordered=False, dtype='category', name='class')# 변수로 저장한 그룹 객체 출력
for i in age_ft.index:
if age_ft[i] == True:
print(grouped.get_group(i))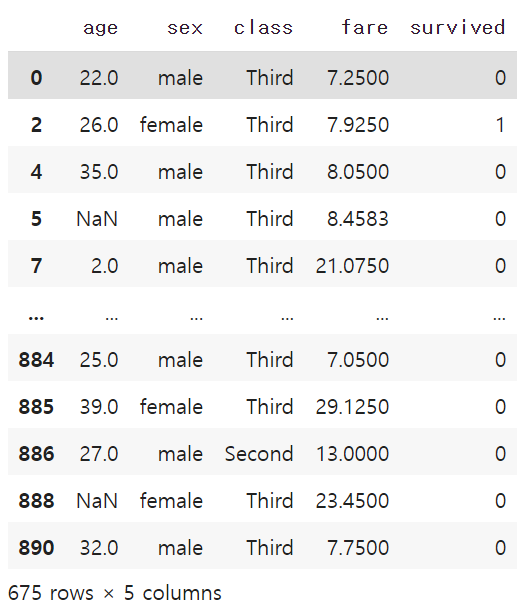
vs filter
# filter는 값 바로 출력 가능
grouped.filter(lambda x: x.age.mean() < 30)'Python > Numpy & Pandas' 카테고리의 다른 글
| [Pandas] 피벗 테이블(Pivot Table) & 멀티 인덱스(MultiIndex) (0) | 2022.10.10 |
|---|---|
| [Pandas] 데이터프레임 연결 (concat, merge, join) (0) | 2022.10.07 |
| [Pandas] 함수 매핑(mapping) / apply, applymap, pipe (0) | 2022.10.06 |
| [Pandas] 시계열 데이터 생성, 변환, 분리, 인덱싱(to_datetime, to_period, date_range, period_range 등) (0) | 2022.10.05 |
| [Pandas] 범주형(category) 데이터처리 / 구간분할(pd.cut, np.histogram) (0) | 2022.10.04 |
'Python/Numpy & Pandas' Related Articles
more



